What the [MASK]? Making Sense of Language-Specific BERT Models
What the [MASK]? Making Sense of Language-Specific BERT Models
Abstract
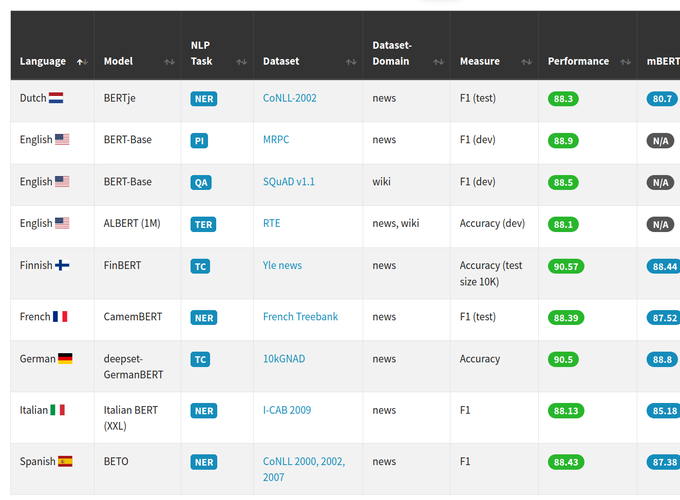
Recently, Natural Language Processing (NLP) has witnessed an impressive progress in many areas, due to the advent of novel, pretrained contextual representation models. In particular, Devlin et al. (2019) proposed a model, called BERT (Bidirectional Encoder Representations from Transformers), which enables researchers to obtain state-of-the art performance on numerous NLP tasks by fine-tuning the representations on their data set and task, without the need for developing and training highly-specific architectures. The authors also released multilingual BERT (mBERT), a model trained on a corpus of 104 languages, which can serve as a universal language model. This model obtained impressive results on a zero-shot cross-lingual natural inference task. Driven by the potential of BERT models, the NLP community has started to investigate and generate an abundant number of BERT models that are trained on a particular language, and tested on a specific data domain and task. This allows us to evaluate the true potential of mBERT as a universal language model, by comparing it to the performance of these more specific models. This paper presents the current state of the art in language-specific BERT models, providing an overall picture with respect to different dimensions (i.e. architectures, data domains, and tasks). Our aim is to provide an immediate and straightforward overview of the commonalities and differences between Language-Specific (language-specific) BERT models and mBERT. We also provide an interactive and constantly updated website that can be used to explore the information we have collected, at https://bertlang.unibocconi.it.